重磅AI芯片深度报告来袭,一文读懂AI芯片
摘要 摘要:随着人工智能持续高速发展,AI在智能安防、无人驾驶、新零售、智能机器人等几大行业不断落地,工信部提前发放5G商用牌照,人工智能和5G将引爆下一轮智能化热潮,其中智能化核心是AI芯片,AI芯片作为持续高速增长的市场,有望成长至300亿美元的体量,传统芯片巨头、互联网巨头、创业公司份份入场,不同细
摘要:随着人工智能持续高速发展,AI在智能安防、无人驾驶、新零售、智能机器人等几大行业不断落地,工信部提前发放5G商用牌照,人工智能和5G将引爆下一轮智能化热潮,其中智能化核心是AI芯片,AI芯片作为持续高速增长的市场,有望成长至300亿美元的体量,传统芯片巨头、互联网巨头、创业公司份份入场,不同细分赛道的AI芯片公司面临不同的机会与挑战。
本期报告从AI芯片分类及技术特点说起,深入剖析AI芯片产业链,从几大AI芯片应用场景看AI芯片的未来发展机会和挑战,并且分析了AI芯片不同细分领域代表性企业,最后提出AI芯片投资的一些建议,希望对AI芯片创业者和投资人一些启示。
来源 | 汉理资本
作者 | 汉理资本高级分析师 赵会博
报告获取通道:关注汉理资本微信公众号(ID:hanliziben),后台回复“AI芯片报告”,获取 PDF 版完整研究报告下载地址。
1 人工智能芯片定义及分类
1、人工智能芯片概述
人工智能(Artificial Intelligence,AI)芯片,从广义上来看,面向人工智能应用的芯片都可以称为AI 芯片。但是通常意义上的AI芯片指的是针对人工智能算法做了特殊加速设计或者经过软硬件优化的芯片,现阶段,这些人工智能算法一般以深度学习算法为主,也可以包括其它机器学习算法。
2、人工智能芯片分类
AI芯片根据技术架构来分类可以分成GPU、FPGA、ASIC、神经拟态芯片;根据功能分类,可以分成训练芯片和推断芯片;根据应用场景可以分为服务器端(云端)芯片和终端(边缘端)芯片。
图1:AI芯片按照技术架构分类

具体介绍如下:
(1)AI芯片按技术架构分类
GPU(Graphics Processing Unit,图形处理单元):在传统的CPU结构中,CPU并不只是数据运算,还需要执行存储读取、指令分析、分支跳转等命令。深度学习算法通常需要进行海量的数据处理,用CPU执行算法时,CPU将花费大量的时间在数据/指令的读取分析上,因此计算效率非常低。而GPU的大部分晶体管是计算单元,控制相对简单,使得GPU的计算速度远高于CPU,同时拥有更强大的浮点运算能力,适合并行计算,因此广泛应用于深度学习算法。
但GPU无法单独工作,必须由CPU进行控制调用才能工作,而且功耗比较高。
半定制化的FPGA:FPGA(Field Programmable GateArray)全称 “现场可编程门阵列 ”, 其基本原理是在FPGA芯片内集成大量的基本门电路以及存储器,用户可通过更新FPGA配置文件来定义这些门路以及存储器之间的连接。
与GPU不同,FPGA同时拥有硬件流水线并行和数据并行处理能力,适用于以硬件流水线方式处理一条数据,且整数运算性能更高,因此常用于深度学习算法中的推断阶段。不过FPGA通过硬件的配置实现软件算法,因此在实现复杂算法方面有一定的难度。将FPGA和CPU对比可以发现两个特点,一是FPGA没有内存和控制所带来的存储和读取部分,速度更快,二是FPGA没有读取指令操作,所以功耗更低。劣势是价格比较高、编程复杂、整体运算能力不是很高。目前国内的AI芯片公司如深鉴科技就提供基于FPGA的解决方案。
全定制化ASIC:ASICc(Application-Specific Integrated Circuit)专用集成电路,是专用定制芯片,即为实现特定要求而定制的芯片。定制的特性有助于提高ASIC的性能功耗比,缺点是电路设计需要定制,相对开发周期长,功能难以扩展。但在功耗、可靠性、集成度等方面都有优势,尤其在要求高性能、低功耗的移动应用端体现明显。谷歌的TPU、寒武纪的GPU,地平线的BPU都属于ASIC芯片。谷歌的TPU比CPU和GPU的方案快30至80倍,与CPU和GPU相比,TPU把控制电路进行了简化,因此减少了芯片的面积,降低了功耗。
GPU作为图像处理器,设计初衷是为了应对图像处理中的大规模并行计算。因此,在应用于深度学习算法时,有三个方面的局限性:第一,应用过程中无法充分发挥并行计算优势。深度学习包含训练和推断两个计算环节,GPU在深度学习算法训练上非常高效,但对于单一输入进行推断的场合,并行度的优势不能完全发挥。第二,无法灵活配置硬件结构。GPU采用SIMT计算模式,硬件结构相对固定。目前深度学习算法还未完全稳定,若深度学习算法发生大的变化,GPU无法像FPGA一样可以灵活的配制硬件结构。第三,运行深度学习算法能效低于FPGA和ASIC。最后,GPU价格较高。
尽管FPGA倍受看好,甚至新一代百度大脑也是基于FPGA平台研发,但其毕竟不是专门为了适用深度学习算法而研发,实际应用中也存在诸多局限:第一,基本单元的计算能力有限。为了实现可重构特性,FPGA内部有大量极细粒度的基本单元,但是每个单元的计算能力(主要依靠LUT查找表)都远远低于CPU和GPU中的ALU模块;第二、计算资源占比相对较低。为实现可重构特性,FPGA内部大量资源被用于可配置的片上路由与连线;第三,速度和功耗相对专用定制芯片(ASIC)仍然存在不小差距;第四,FPGA价格较为昂贵,在规模放量的情况下单块FPGA的成本要远高于专用定制芯片。因此,随着人工智能算法和应用技术的日益发展,以及人工智能专用芯片ASIC产业环境的逐渐成熟,全定制化人工智能ASIC也逐步体现出自身的优势。
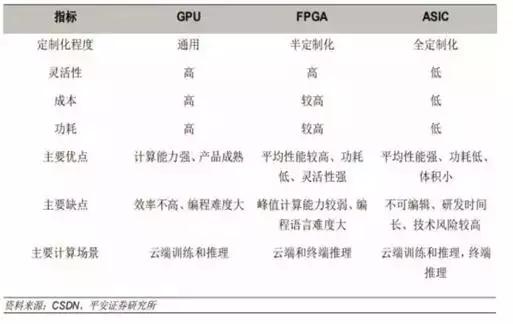
GPU、FPGA、ASIC对比如下:
图2:GPU、FPGA、ASIC性能特点对比
神经拟态芯片:神经拟态计算是模拟生物神经网络的计算机制。神经拟态计算从结构层面去逼近大脑,其研究工作还可进一步分为两个层次,一是神经网络层面,与之相应的是神经拟态架构和处理器,如IBM的TrueNorth芯片,这种芯片把定制化的数字处理内核当作神经元,把内存作为突触。其逻辑结构与传统冯·诺曼构不同:它的内存、CPU和通信部件完全集成在一起,因此信息的处理可以在本地进行,克服了传统计算机内存与CPU之间的速度瓶颈问题。
(2)AI芯片按功能分类
根据机器学习算法步骤,可分为训练(training)和推理(inference)两个环节:
训练环节通常需要通过大量的数据输入,训练出一个复杂的深度神经网络模型。训练过程由于涉及海量的训练数据和复杂的深度神经网络结构,运算量巨大,需要庞大的计算规模,对于处理器的计算能力、精度、可扩展性等性能要求很高。目前市场上通常使用英伟达的GPU集群来完成,Google的TPU2.0/3.0也支持训练环节的深度网络加速。
推理环节是指利用训练好的模型,使用新的数据去“推断”出各种结论。这个环节的计算量相对训练环节少很多,但仍然会涉及到大量的矩阵运算。在推理环节中,除了使用CPU或GPU进行运算外,FPGA以及ASIC均能发挥重大作用。
图3:AI芯片按功能分类

(3)AI芯片按应用场景分类
人工智能主要分为用于服务器端(云端)和用于边缘端两大类。
服务器端:在深度学习的训练阶段,由于数据量及运算量巨大,单一处理器几乎不可能独立完成一个模型的训练过程,因此,负责AI算法的芯片采用的是高性能计算的技术路线,一方面要支持尽可能多的网络结构以保证算法的正确率和泛化能力;另一方面必须支持浮点数运算;而且为了能够提升性能必须支持阵列式结构(即可以把多块芯片组成一个计算阵列以加速运算)。在推断阶段,由于训练出来的深度神经网络模型仍非常复杂,推断过程仍然属于计算密集型和存储密集型,可以选择部署在服务器端。
边缘端(终端、设备端):边缘端AI芯片在设计思路上与服务器端AI芯片有着本质的区别。首先,必须保证很高的计算能效;其次,在高级辅助驾驶ADAS等设备对实时性要求很高的场合,推断过程必须在设备本身完成,因此要求移动端设备具备足够的推断能力。而某些场合还会有低功耗、低延迟、低成本的要求,从而导致边缘端的AI芯片多种多样。
图4:AI芯片按应用场景

2 人工智能芯片市场规模及增速
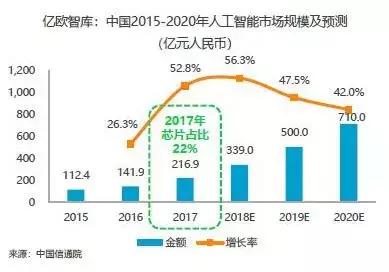
根据中国信通院的数据报告,中国的人工智能市场规模在2018年预计超过300亿人民币,而2019年后将超500亿人民币的规模。市场年度增长率,将从2017年的52.8%上升至2018年的56.3%,然后逐年下降,在2020年剩下42.0%的增长率。其中,2017年芯片销售金额占人工智能市场规模的22%,约47.7亿人民币。
图5:中国2015-2020年人工智能市场规模及预测
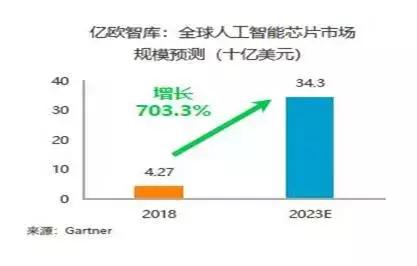
根据Gartner的预测数据,全球人工智能芯片市场规模将在未来五年内呈现飙升,从2018年的42.7亿美元,成长至343亿美元,增长超过7倍,显见AI芯片市场增长空间大。
图6:全球人工智能芯片市场规模预测
3 人工智能芯片产业链及行业特点
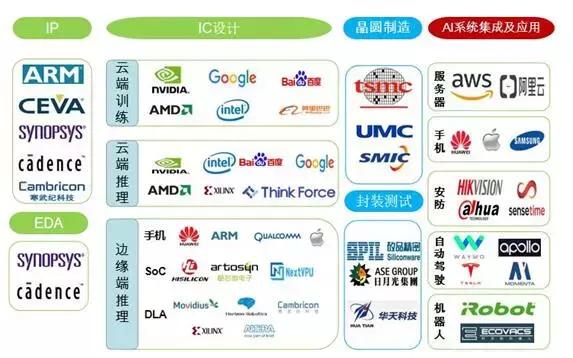
1、AI芯片产业链
AI芯片产业链主要分成,IC设计-制造/封测-系统集成及应用,具体如下图所示。
上游:主要是芯片设计,按照商业模式,可再细分成三种:IP设计、芯片设计代工和芯片设计,大部分公司是IC设计公司。
- IP设计:IP设计相对于芯片设计是在更顶层的产业链位置,以IP核授权收费为主。传统的IP核授权企业是以安谋(arm)为代表,新创的AI芯片企业虽然也会设计出新型IP核,但因授权模式不易以规模效应创造可观收入,新创企业一般不以此作为主要盈利模式。另外还有提供自动化设计(EDAtool)和芯片设计验证工具的cadence和Synopsys,也在积极部署人工智能专用芯片领域。
- 芯片设计:大部分的人工智能新创企业是以芯片设计为主,但在这个领域中存在传统强敌,像是英伟达、英特尔、赛灵思(Xilinx)和恩智浦,因此目前少数AI芯片设计企业会进入传统芯片企业的产品领域,像是寒武纪与英伟达竞争服务器芯片市场,地平线与英伟达及恩智浦竞争自动驾驶芯片市场,其余是在物联网场景上布局,像是提供语音辨识芯片的云知声,提供人脸辨识芯片的中星微,或者是提供边缘智能视觉计算芯片的酷芯微电子。
中游:包含两大类,分别是晶圆制造和封装测试,但晶圆不仅是在封装时测试,制造后会有一次测试,封装后再有一次。
下游:产业链的下游主要为系统集成及应用企业,比如人工智能解决方案商等。应用领域包括服务器、手机、安防、自动驾驶、机器人等领域。
图7:AI芯片产业链
来源:汉理资本根据公开资料整理
2、SOC芯片相比较DLA技术开发难度高
随着AI高速发展,很多AI芯片公司开发了DLA(Deep Learning Accelerator,深度学习加速器),DLA通常是以AI协处理器的形式装载在板上,再另外搭配核心处理器完成任务。然而AI的板上系统使用时往往会有低性能、高价格、高功耗的问题。因此,部分AI芯片公司设计了SoC(System on Chip,称为系统级芯片,或片上系统)。AI芯片公司是将不同功能的芯片集成到一块芯片上,其中会包含核心处理器(CPU)、协处理器(DLA)、存储器和其他零件等。SOC通常拥有更高性能、更低价格、更低功耗,适用于各种终端。
系统芯片开发技术复杂,设计的关键技术包含但不限于以下6项:
(1)总线架构技术;
(2)IP核可复用技术;
(3)软硬件协同设计技术;
(4)异构芯片设计技术;
(5)验证技术;
(6)可测性设计技术。
以上关键技术皆涉及跨学科知识,且开发流程复杂,可多达40个工序,每个工序都需要一位专业工程师负责执行工作,开发过程需要前后反复验证设计,避免流片失败。
系统芯片(SoC)设计与AI加速器(DLA)设计相比,前者的设计难度更高,两者的差异主要体现在以下:
第一,系统芯片设计需要更加了解整个系统的运作,借以定义合理的芯片架构,使得软硬件集成达到系统最佳工作状态;
第二,系统芯片设计是以IP核复用为基础,因此基于IP模块的大规模集成电路设计是系统芯片实现的关键。因此,SoC芯片企业,首先碰到的问题是人才技术储备问题,需要大量的有丰富设计经验的软硬件技术人才。
3、AI芯片开发成本高,融资至关重要
对于芯片设计企业来说,从开发到成品的IP核授权、开发软件、流片、芯片制造/封测等费用是无可避免的开发成本,成本高昂,一旦芯片流片未成功,前期投入都会形成巨大损失。因此非常考验技术团队过往的工程化经验。
一般而言,ASIC芯片的开发费用相当高,根据IBS的估算数据,按照不同制程,65nm芯片开发费用有2850万美元,5nm芯片开发费用则为54220万美元,差距甚大。在人工智能应用领域,依据芯片的部署位置和任务需求,会采用不同的制程,云端追求高算力,因此会采用先进制程,在云端会采用7nm制程,像是寒武纪的MLU100芯片;在边缘端和部分移动端设备会采用28nm、22nm、16nm或10nm制成的芯片,根据不同的场景和公司芯片设计架构来确定。终端设备中比较常采用的是65nm和28nm制成的芯片,端看芯片的集成程度,若做为系统芯片使用,宜采用28nm制成的设计。但以上分类并非严格界定,芯片设计的工艺是取决于客户的需求,像是智慧型手机的系统芯片设计已经采用7nm制程。
图8: 65nm-5nm制程的芯片开发费用
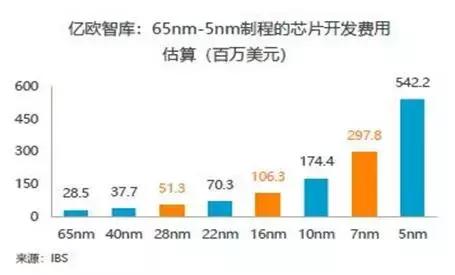
来源:亿欧智库;IBS
根据亿欧智库的调查,目前国内AI芯片的开发费用低于IBS的估算金额。系统芯片的开发费用仅为IBS估算金额的20-50%,协处理器又仅为系统芯片的30-40%。以终端常用的28nm制成的芯片为例,AI系统芯片的开发费用约为2500万美元,AI协处理器开发费用约为800万美元。
即便AI芯片设计的费用相对而言比较低,但高达2500万美元以上的芯片开发费用,加上长达1-3年的开发周期,AI芯片企业在融资的早期阶段需要投资人的大量资金注入,才能够撑过没有产品销售的阶段,并且成功踏出第一步。
根据亿欧智库不完全统计,目前中国的一级投资市场上,以AI芯片设计为主要业务的企业中,有20家参与融资活动。按照投融资阶段分类,有4家企业在A轮之前的阶段(天使轮和Pre-A轮),11家企业在A轮阶段(A和A+轮),3家在B轮阶段,仅有2家在C轮阶段之后。其中,地平线和寒武纪都是独角兽企业,估值分别为30亿美元和25亿美元。
图9:中国AI芯片行业融资轮次与融资总额
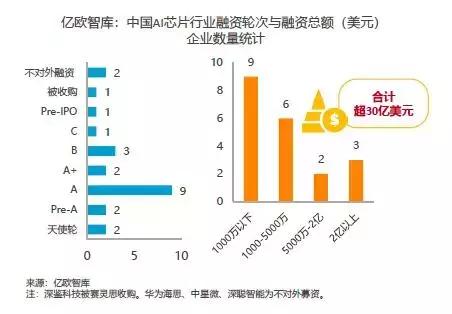
来源:亿欧智库
上述在天使轮到Pre-IPO融资阶段的芯片企业中,仅有3家融资总额超过2亿美元以上,分别是比特大陆、地平线和寒武纪;有2家企业融资总额在5000万美元到2亿美元之间,分别是ThinkForce(熠知电子)和触景无限。其余15家企业的融资总金额都在5000万美元以下,甚至有9家企业的融资总金额不超过1000万美元。根据前述ASIC芯片开发的成本估算,融资总金额不足5000万美元的芯片企业需谨慎使用资金,避免在下一期融资到账前发生资金链断裂。
4 人工智能芯片主要应用场景
由于AI芯片是面对人工智能用途或深度学习应用的芯片,芯片与算法的结合程度高,市场规模大、市场容易放量是AI芯片企业寻求落地场景的主要考虑因素,因此接下来将会按照用途、部署位置以及应用场景来讨论AI芯片的落地及相关市场规模。
1、云端市场:需求持续上升,服务器AI芯片的市场前景乐观
按照AI芯片的部署位置,可以简单将AI芯片市场分成云端市场和终端市场两大类,具有云计算需求的行业主要是金融业、医疗服务业、制造业、零售/批发以及政府部门五大行业。
图10:全球云计算支出金额与增长率
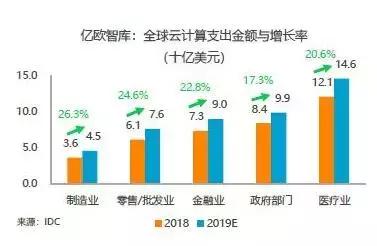
来源:亿欧智库;IDC
根据IDC数据,云计算需求增长快速,全球云计算支出在2018年至2019年将迎来大幅度增长,五大行业的最低支出增长17.3%,最高26.3%,其中以医疗业的需求最高,超100亿美元。另外,根据IDC数据,全球服务器设备的出货量在2018年第三季达320万台,营收达234亿美元以上,按照出货增长率来看,2018年全年营收或可达1000亿美元以上,远超过2017年营收669亿美元。
图11:全球服务器设备营收与出货量
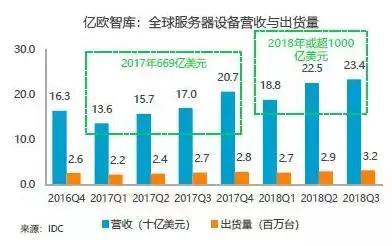
来源:亿欧智库;IDC
云计算支出的增长快速,代表云计算的需求旺盛,加上服务器的出货量持续提升,也代表部署服务器的AI芯片的需求量跟着提升,云端芯片的市场未来将快速增长。
数据中心是AI训练芯片应用的最主要场景,主要涉及芯片是GPU和专用芯片(ASIC)。如前所述,GPU在云端训练过程中得到广泛应用。目前,全球主流的硬件平台都在使用英伟达的GPU进行加速,AMD也在积极参与。亚马逊网络服务 AWS EC2、Google Cloud Engine(GCE)、IBM Softlayer、Hetzner、Paperspace 、LeaderGPU、阿里云、腾讯云等计算平台都使用了英伟达的GPU产品提供深度学习算法训练服务。
在云端推理市场上,由于芯片更加贴近应用,市场更多关注的是响应时间,需求也更加的细分。除了主流的CPU+GPU异构之外,还可通过CPU+FPGA/ASIC进行异构。目前,英伟达在该市场依然保持着领军位置,但是FPGA的低延迟、低功耗、可编程性优势(适用于传感器数据预处理工作以及小型开发试错升级迭代阶段)和ASIC的特定优化和效能优势(适用于在确定性执行模型)也正在凸显,赛灵思、谷歌、Wave Computing、Groq、寒武纪、比特大陆等企业市场空间也在扩大。
2、智能手机:手机出货量年超14亿部,但新创AI芯片企业难进入
终端应用基本上是推理芯片。当前的终端市场上,主要有两大落地场景,第一个是智慧型手机,第二个是物联网设备,包括智能安防摄像头等。手机又被称作移动端,在智慧型手机上,AI芯片主要是负责拍照后的图像处理任务,以及协助智慧助理的语音处理任务。
2017 年 9 月,华为在德国柏林消费电子展发布了麒麟 970 芯片,该芯片搭载了寒武纪的 NPU,成为“全球首款智能手机移动端 AI 芯片” ,2017 年 10 月中旬 Mate10 系列新品(该系列手机的处理器为麒麟 970)上市。搭载了 NPU 的华为 Mate10 系列智能手机具备了较强的深度学习、本地端推断能力,让各类基于深度神经网络的摄影、图像处理应用能够为用户提供更加完美的体验。
而苹果发布以 iPhone X 为代表的手机及它们内置的 A11 Bionic 芯片。A11 Bionic 中自主研发的双核架构 Neural Engine(神经网络处理引擎),它每秒处理相应神经网络计算需求的次数可达 6000 亿次。这个 Neural Engine 的出现,让 A11 Bionic 成为一块真正的 AI 芯片。 A11 Bionic 大大提升了 iPhone X 在拍照方面的使用体验,并提供了一些富有创意的新用法。
虽然目前全球手机销售量出现衰退,但根据IDC的数据,全球智慧型手机出货量已经连续两年超过14亿部,全球前5大厂商中有3家中国企业,按2018年出货量高低依序为,华为2.06亿部、小米1.23亿部,和OPPO1.13亿部。
表面上,智慧型手机每年的AI芯片出货量可以轻松超过1000万,但事实上,AI芯片(或称AI加速器)是内嵌在手机的系统芯片(SoC)中,手机品牌商并不会向能提供系统芯片以外的企业采购芯片,于是缺乏设计手机系统芯片能力的新创AI芯片企业,只能透过IP核授权的方式来参与手机供应链,但是传统手机芯片企业,像是高通和联发科也有能力自行设计AI加速器的IP核,因此新创AI芯片企业难以在手机市场中获利,即便能打入IP授权市场,也不能当做主业务支持企业的营运。手机市场对于新创AI芯片企业来说,是一个看得到却吃不到的大饼。
3、计算机视觉(Computer Vision)
计算机视觉是全球及国内AI最为确定以及最大的市场,包括智能安防、新零售等细分应用场景。
(1)智能安防
安防市场是全球及国内AI最为确定以及最大的市场,尤其是AI中的图像识别和视频处理技术正在全面影响安防产业。Mordor Intelligence分析称2017年全球视频监控系统市场规模为349亿美元,预计2023年将达到826亿美元,预计2018年-2023年复合增长率为15.41%。中国《财经》数据显示,2017年中国安防产业的产值达到4500亿人民币,但所有AI安防产品产值不到20亿,AI在安防行业技术渗透率不到1%,存在巨大的提升空间。
智能安防系统的建立,离不开AI芯片及算法的提升,在安防产品中,摄像头、交换机、IPC(网络摄像机)、硬盘刻录机、各类服务器等设备都需要芯片,这些芯片也决定了整个安防系统的整体功能、技术指标、能耗以及成本。在安防芯片中,最为关注的还是四类与监控相关的芯片(ISP芯片、DVR SoC芯片、IPC SoC芯片、NVR SoC芯片)。
ISP芯片(Image Signal Processing,图像信号处理)主要负责对前端摄像头所采集的原始图像信号进行处理;DVR(DigitalVideoRecorder,数字硬盘录像机)SoC芯片主要用于模拟音视频的数字化、编码压缩与存储;IPC (IP Camera,IP摄像机)SoC芯片通常集成了嵌入式处理器(CPU)、图像信号处理(ISP)模块、视音频编码模块、网络接口模块等,具备入侵探测、人数统计、车辆逆行、丢包检测等一些简单的视频分析功能;NVR (Network Video Recorder,网络硬盘录像机) SoC芯片主要用于视频数据的分析与存储,功能相对单一,但由于多与IPC联合使用,市场增长也较快。
通常情况下,安防视频监控模拟摄像机的核心部件包括一颗图像传感器和一颗ISP芯片,安防视频监控网络摄像机的核心部件包括一颗图像传感器和一颗IPC SoC芯片。单从国内来看,未来国内视频监控行业增速仍将保持12%-15%左右的水平增长,其中网络监控设备增长更为迅速,相关芯片产品需求十分旺盛。
安防AI芯片市场上,除了传统芯片以及安防厂商,还有大量的创业企业在涌入。国外芯片厂商主要有英伟达、英特尔、安霸、TI、索尼、特威、三星、谷歌等;国内厂商主要有海思(华为)、国科微、中星微、北京君正、富瀚微、景嘉微、寒武纪、深鉴科技、云天励飞、中科曙光等。英伟达、英特尔等企业凭借着通用处理器以及物联网解决方案的优势,长期与安防巨头如海康、大华、博世等保持紧密联系;国内寒武纪、地平线、酷芯微等企业,都有AI芯片产品面世,海思本身就有安防摄像机SoC芯片,在新加入AI模块之后,竞争力进一步提升。
从安防行业发展的趋势来看,随着5G和物联网的快速落地,“云边结合”将是行业最大的趋势,云端芯片国内企业预计很难有所突破,但是边缘侧尤其是视频处理相关AI芯片还是有较大潜力,国产化替代将加速。但也看到,AI芯片离在安防领域实现大规模快速落地仍有距离。
(2)新零售
受益于零售行业的数字化转型,人工智能已渗透到零售各个价值链环节。随着各大零售企业加入电商巨头和科技企业纷纷布局人工智能,人工智能在零售行业的应用从个别走向聚合,零售行业拉开利用人工智能转型的大幕。人工智能零售行业应用落地在全球高速增长。据Gartner预测,到2020年,85%的消费者互动将通过人工智能实现自动化管理。Global Market Insights数据显示,2018—2024年间全球人工智能在零售领域应用年均复合增长率(CAGR)超过40%,应用市场规模在2024年达到80亿美元,其中亚太市场CAGR超过45%,主要由中国和印度市场带动。
从技术领域来看,视觉识别/搜索技术相关应用CAGR 45%,机器学习相关应用CAGR超过42%。人工智能在零售领域应用为绕人、货、场、链进行构建,不同场景面向不同应用需求:
- 面向消费者的需求预测、个性化营销、购买体验以及智能客服,主要诉求是持续有效的吸引消费者参与;
- 面向货品应用主要有利用智能货架协助支付、盘点、促销、定价等功能;
- 面向门店的店铺选址、店内购物体验、无人店铺等,主要诉求为实现店铺投资的效益最大化;
- 面向供应链的智能定价、智能配送和仓储,主要诉求是效率的提升。
- 具体如下:
图12:新零售各个场景
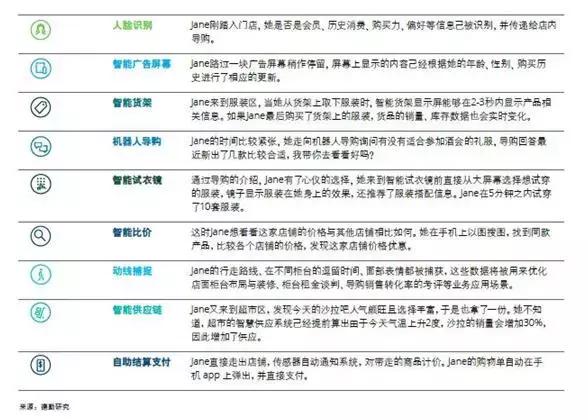
其中,人脸识别、智能广告机、机器人导航、智能试衣镜、动作分析、自助结算都需要AI视觉芯片,AI视觉芯片在新零售场景使用比较广泛。人脸识别对于AI视觉芯片算力要求不太高,动作分析由于需要对多帧图像进行分析,算力要求较高。国内酷芯微电子采用独立研发并量产的第一代AI芯片,与国内TOP电商公司等针对新零售场景做出了一系列的解决方案,性能媲美采用国外Movidius公司的解决方案,价格远低于它,性价比非常高,有望降低新零售实施成本,推动新零售快速落地。
4、自动驾驶
自动驾驶汽车装备了大量的传感器、摄像头、雷达、激光雷达等车辆自主运行需要的部件,每秒都会产生大量的数据,根据英特尔CEO 测算,假设一辆自动驾驶汽车配臵了GPS、摄像头、雷达和激光雷达等传感器,则上述一辆自动驾驶汽车每天将产生约4000GB 待处理的传感器数据。
如何使自动驾驶汽车能够实时处理如此海量的数据,并在提炼出的信息基础上得出合乎逻辑且形成安全驾驶行为的决策,需要强大的计算能力做支持。考虑到自动驾驶对延迟要求很高,传统的云计算面临着延迟明显、连接不稳定等问题,这意味着一个强大的车载计算平台(芯片)成为了刚需。要实现L3级别自动驾驶,车载计算平台的计算力需求至少在20T 以上,而L4/L5级别对算力要求将呈现指数级上升,车载计算芯片将蕴含巨大市场机会。
目前,自动驾驶所使用的芯片主要基于GPU、FPGA和ASIC三条技术路线。但由于自动驾驶算法仍在快速更迭和进化,因此大多自动驾驶芯片使用GPU+FPGA的解决方案。未来算法稳定后,ASIC将成为主流,从应用性能、单位功耗、性价比、成本等多维度分析,适用于车载的ASIC 架构芯片具备相当优势。按照 SAE International 的自动驾驶等级标准,目前已商用的自动驾驶芯片基本处于高级驾驶辅助系统(ADAS)阶段,可实现 L1-L2 等级的辅助驾驶和半自动驾驶 ( 部分宣称可实现L3 的功能 ) ;而面向 L4-L5 超高度自动驾驶及全自动驾驶的 AI 芯片离规模化商用仍有距离。
AI芯片用于自动驾驶之后,对传统的汽车电子市场冲击较大,传统的汽车电子巨头(恩智浦、英飞凌、意法半导体、瑞萨)虽然在自动驾驶芯片市场有所斩获,但风头远不及英特尔、英伟达、高通甚至是特斯拉。国内初创企业如地平线、寒武纪也都在积极参与。在自动驾驶芯片领域进展最快以及竞争力最强的是英特尔和英伟达,英特尔强在能耗,英伟达则在算力和算法平台方面优势明显。
英特尔进入自动驾驶芯片市场虽然较晚,但通过一系列大手笔收购确立了其在自动驾驶市场上的龙头地位。2016年,公司出资167亿美元收购了FPGA龙头Altera;2017年3月以153亿美元天价收购以色列ADAS公司Mobileye,该公司凭借着EyeQ系列芯片占据了全球ADAS 70%左右的市场,为英特尔切入自动驾驶市场创造了条件。收购完成之后,英特尔形成了完整的自动驾驶云到端的算力方案——英特尔凌动/至强+Mobileye EyeQ+Altera FPGA。英特尔收购Mobileye之后,后者也直接推出了EyeQ5,支持L4-L5自动驾驶,预计在2020年量产。
英伟达在汽车AI芯片的竞争中不落下风。英伟达在2015年推出了世界首款车载超级计算机Drive PX,紧接着2016年推出Drive PX2,2018年推出新一代超级计算机Drive Xavier,同年,基于双Drive Xavier芯片针对自动驾驶出租车业务的Drive PX Pegasu计算平台面世。2019 CES上,英伟达推出了全球首款商用L2+自动驾驶系统NVIDIA DRIVE AutoPilot。DRIVE AutoPilot的核心是Xavier 系统级芯片。该芯片处理器算力高达每秒30万亿次,已经投产。
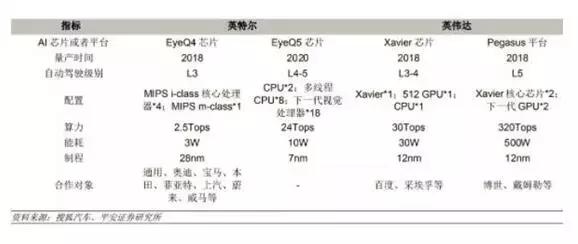
图13:英特尔与英伟达对比
5、机器人
机器人是人工智能行业最早的落地形态,也是现在和将来重要的应用方向。机器人主要包括两类——制造环境下的工业机器人和非制造环境下的服务机器人。工业机器人主要是面向工业领域的多关节机械手或多自由度机器人。服务机器人则是除工业机器人之外的、用于非制造业并服务于人类的各种先进机器人。
随着云物移大智等信息及智能化技术的发展,机器人在某些领域的工作效率高于人类,并在工业和服务场景中得到了大量应用。根据IDC的一份报告预测,2018年全球机器人和无人机解决方案的支出总额将达到1031亿美元(约合6525亿元),与2017年相比增长22.1%。
(1)工业机器人
据国际机器人联盟统计,2017年,全球工业机器人产量达到38.1万台,同比增长30%,预计2018-2021年全球工业机器人产量将保持10%以上增速增长,2021年产量预计将达到63.0万台。中国是全球最大的工业机器人生产国,2017年产量达到13.79万台,同比大幅增长60%。
随着机器视觉的技术逐渐成熟,可以将机器视觉应用于工业机器人领域,通过TOF + 普通摄像头,实现深度信息和普通视频信息融合,可广泛应用于各种智能行动机器人,在智能物流机器人领域将有望不规模采用,该解决方案的关键是AI视觉芯片及算法。
(2)服务机器人
服务机器人主要用于物流、防务、公共服务、医疗等领域,虽然规模不大,但是增长迅速。2017年全球产量为10.95万台,同比大幅增长85%。预计2018年全球专业服务机器人产量将达到16.53万台,同比增长32%,2019-2021年平均增速将保持在21%左右。
智能服务机器人搭载语音交互、远程视频、本地服务、家居控制等功能,以早教和娱乐为卖点使得此类机器人快速打入消费级市场。智能服务机器人需要搭载AI视觉芯片才能很好地进行人和物体识别,并进行智能化移动。
(3)扫地机器人
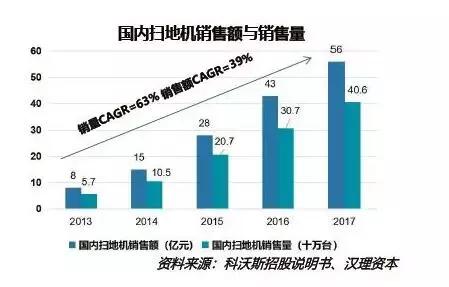
随着生活节奏加快和工作压力增大,消费者希望从繁琐的家庭劳务中解脱出来。扫地机器人在此背景下应运而生并成为家庭中负责劳动的入门级智能产品。扫地机器人因需求明确、任务单一,因此发展较为成熟。2017年中国扫地机器人零售规模已达56亿元,线上渠道占比近90%,成为扫地机器人销售的主阵地。2013 年到2017 年,国内扫地机器人销售量从57 万台上升至406 万台,销售额从8 亿元上升到56 亿元,4 年CAGR 超过60%。估算扫地机器人保有量在1200万台左右,中国城镇家庭约2.5 亿户,2017 年扫地机器人在中国的城镇家庭渗透率不到5%。北美市场以美国市场为主,美国拥有1.3 亿户家庭,iRobot 估算扫地机器人在美国家庭的渗透率约10%。中国扫地机器人市场空间广阔。
图14:国内扫地机销售额与销售量
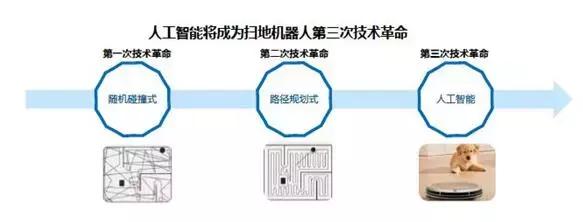
目前,国内扫地机器人渗透率不高的主要原因是扫地机器人不够智能、扫地效果较差,由于传统扫地机器人采用SLAM进行导航,而不能智能识别电线、衣袜等,容易被缠绕,用户体验较差。而第三代扫地机器人采用双摄像头,全景人工智能建模,360度无死角,识别人脸、家具、门、 垃圾、回充座等,并做出相应反应,高智能规划清扫路径。
国内酷芯微电子公司率先实现Edge端单芯片完成VSLAM和目标物体识别,预计将成为下一代以扫地机为代表的家庭机器人的首选方案。
图15:扫地机器人技术路径演进
资料来源:汉理资本
(4)无人机
目前国内消费无人机经过高速发展期,普通民众对无人机的认可程度和需求度达到一定水平,市场增长速度放缓。而在工业无人机,由于有电力巡检、环境监测、森林防火、安防监控、快递送货等更多的场景出现,市场持续升温。
6、其他应用场景
智能家居近年来也成为人工智能重要的落地场景。从技术应用上讲,人类90%的信息输出是通过语音,80%的是通过视觉,智能家居领域应用最多的就是智能语音交互技术。近年来,正是看到语音交互技术与智能家居深度融合的潜力,谷歌、苹果、微软均将其作为进入智能家居领域的重要切入口,发布了多款软硬件平台,如亚马逊推出的智能音箱设备。国内智能语音龙头企业科大讯飞较早就切入了该领域,联合地产商推出了硬件平台魔飞(MORFEI)平台,电视、咖啡机、电灯、空调、热水器等产品都能通过融入相关平台实现智能化。
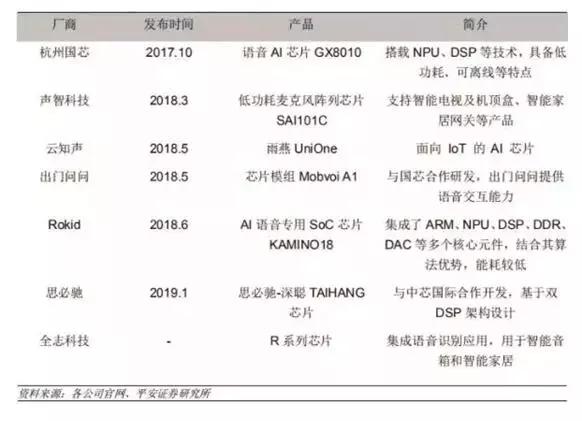
当前,无论是智能音箱还是其他智能家居设备,智能功能都是在云端来实现,但云端存在着语音交互时延的问题,对网络的需求限制了设备的使用空间,而且由此还带来了数据与隐私危机。为了让设备使用场景不受局限,用户体验更好,端侧智能已成为一种趋势,语音AI芯片也随之切入端侧市场。国内主要语音技术公司凭借自身在语音识别、自然语言处理、语音交互设计等技术上的积累,开始转型做AI语音芯片集成及提供语音交互解决方案,包括云知声、出门问问、思必驰以及Rokid。
市场上主流的AI语音芯片,一般都内置了为语音识别而优化的深度神经网络加速方案,以实现语音离线识别。随着算法的精进,部分企业的语音识别能力得到了较快提升,尤其是在远场识别、语音分析和语义理解等方面都取得了重要进展。云知声在2018年5月,推出语音AI芯片雨燕,并在研发多模态芯片,以适应物联网场景,目前公司芯片产品已经广泛用于智能家电如空调之中;出门问问也在2018年推出了AI语音芯片模组“问芯”MobvoiA1;Rokid也发在2018年发布了AI语音芯片KAMINO18;思必驰利用其声纹识别等技术优势,2019年初推出基于双DSP架构的语音处理专用芯片TH1520,具有完整语音交互功能,能实现语音处理、语音识别、语音播报等功能。
由于语音芯片市场过于细碎,需要企业根据场景和商业模式需要设计出芯片产品,这对传统的通用芯片企业的商业模式是一种颠覆,以致于在2018年以前都很少有芯片巨头进入该领域,这也给了国内语音芯片企业较大的施展空间。而对算法公司来说,通过进入芯片市场,进而通过解决方案直接面向客户和应用场景,通过实战数据来训练和优化算法。
图16:国内语音芯片企业
5 AI芯片国内外代表性企业介绍
人工智能芯片技术领域的国内代表性企业包括中科寒武纪、中星微、地平线机器人、深鉴科技、、百度、华为、酷芯微等,国外包括英伟达、 AMD、 Google、高通、Nervana Systems、 Movidius、 IBM、 ARM、 CEVA、 MIT/Eyeriss、苹果、三星等。
1、云端训练
(1)英伟达:AI芯片市场的领导者,计算加速平台广泛用于数据中心、自动驾驶等场景
英伟达创立于1993年,最初的主业为显卡和主板芯片组。其主板芯片组主要客户以前是AMD,但是在AMD收购ATI推出自研芯片组之后,英伟达在该领域的优势就荡然无存。于是,公司全面转向到GPU技术研发,同时进入人工智能领域。2012年,公司神经网络技术在其GPU产品的支持下取得重大进展,并在计算机视觉、语音识别、自然语言处理等方面得到广泛应用。
2016年,全球人工智能发展加速,英伟达迅速推出了第一个专为深度学习优化的Pascal GPU。2017年,英伟达又推出了性能相比Pascal提升5倍的新GPU架构Volta,同时推出神经网络推理加速器TensorRT 3。至此,英伟达完成了算力、AI构建平台的部署,也理所当然成为这一波人工智能热潮的最大受益者和领导者。公司的战略方向包括人工智能和自动驾驶。
人工智能方面。英伟达面向人工智能的产品有两个,Tesla系列GPU芯片以及DGX训练服务器。Tesla系列是专门针对AI深度学习算法加速设计GPU芯片,DGX则主要是面向AI研究开发人员设计的工作站或者超算系统。2018年,公司包含这两款产品的数据中心业务收入大幅增长52%,其中Tesla V100的强劲销售是其收入的主要来源。
自动驾驶方面。英伟达针对自动驾驶等场景,推出了Tegra处理器,并提供了自动驾驶相关的工具包。2018年,基于Tegra处理器,英伟达推出了NVIDIA DRIVE AutoPilot Level 2+,并赢得了丰田、戴姆勒等车企的自动驾驶订单。同时,2018年,公司也正在积极推动Xavier自动驾驶芯片的量产。
值得关注的是,英伟达还正在通过投资和并购方式继续加强在超算或者数据中心方面的业务能力。2019年3月,英伟达宣称将斥资69亿美元收购Mellanox。Mellanox是超算互联技术的早期研发和参与者。通过与Mellanox的结合,英伟达将具备优化数据中心网络负载能力的能力,其GPU加速解决方案在超算或者数据中心领域的竞争力也将得到显著提升。
(2) 谷歌:TPU芯片已经实现从云到端,物联网TPU Edge是当前布局重点
谷歌可谓是AI芯片行业的一匹黑马,但是竞争力强劲,在Training市场目前能与NVIDIA竞争的就是Google。谷歌拥有大规模的数据中心,起初同其他厂商的数据中心一样,都采用CPU+GPU等异构架构进行计算加速,用来完成图像识别、语音搜索等计算服务。但是,随着业务量的快速增长,传统的异构模式也很难支撑庞大的算力需求,需要探索新的高效计算架构。同时,谷歌也需要通过研发芯片来拓展AI平台TensorFlow的生态。因此,Google 在 2016 年宣布独立开发一种名为 TPU 的全新的处理系统。 TPU 是专门为机器学习应用而设计的专用芯片。通过降低芯片的计算精度,减少实现每个计算操作所需晶体管数量的方式,让芯片的每秒运行的操作个数更高,这样经过精细调优的机器学习模型就能在芯片上运行得更快,进而更快地让用户得到更智能的结果。 在 2016 年 3 月打败了李世石和 2017 年 5 月打败了柯杰的阿尔法狗,就是采用了谷歌的 TPU 系列芯片。
Google I/O-2018 开发者大会期间,正式发布了第三代人工智能学习专用处理器 TPU 3.0。TPU3.0 采用 8 位低精度计算以节省晶体管数量, 对精度影响很小但可以大幅节约功耗、加快速度,同时还有脉动阵列设计,优化矩阵乘法与卷积运算, 并使用更大的片上内存,减少对系统内存的依赖。 速度能加快到最高 100PFlops(每秒 1000 万亿次浮点计算)。
目前Google并不直接出售TPU芯片,而是结合其开源深度学习框架TensorFlow为AI开发者提供TPU云加速服务,以此发展AI生态。
从谷歌TPU的本质来看,它是一款ASIC(定制芯片),针对TensorFlow进行了特殊优化,因此该产品在其他平台上无法使用。第一代Cloud TPU仅用于自家云端机房,且已对多种Google官方云端服务带来加速效果,例如Google街景图服务的文字处理、Google相簿的照片分析、甚至Google搜寻引擎服务等。Cloud TPU也在快速改版,2017年推出第二代,2018年推出第三代芯片TPU 3.0。同时,谷歌对TPU的态度也更为开放,之前主要是自用,目前也在对用户开放租赁业务,但没有提供给系统商。
除了云端,谷歌针对边缘端推理需求快速增长的趋势,也在开发边缘TPU芯片。2017年11月,Google推出轻量版的TensorFlow Lite(某种程度取代此前的TensorFlow Mobile),使得能耗有限的移动设备也能支持TensorFlow,2018年推出的Edge TPU芯片即是以执行TensorFlow Lite为主,而非TensorFlow。Edge TPU性能虽然远不如TPU,但功耗及体积大幅缩小,适合物联网设备采用。Edge TPU可以自己运行计算,不需要与多台强大计算机相连,可在传感器或网关设备中与标准芯片或微控制器共同处理AI工作。
按照谷歌的规划,Edge TPU将提供给系统商,开放程度将进一步提升。如果Edge TPU推广顺利,支持的系统伙伴将进一步增多,谷歌将尽快推出下一代Edge TPU产品。即使推广不顺利,Google也可能自行推出Edge网关、Edge设备等产品。
(3) 英特尔加速向数字公司转型,通过并购+生态优势发力人工智能
英特尔作为传统的CPU设计制造企业,在传统PC、服务器市场有着绝对的统治力。随着互联网时代的到来以及个人电脑市场的饱和,公司也在开始加快向数字公司转型。尤其在人工智能兴起之后,英特尔凭借着技术和生态优势,打造算力平台,形成全栈式解决方案。
英特尔主要产品为CPU、FPGA以及相关的芯片模组。虽然CPU产品在训练端的应用效率不及英伟达,但推理端优势较为明显。英特尔认为,未来AI工作周期中,推理的时长将是训练时长的5倍甚至10倍,推理端的芯片需求也会放量。同时,即使是云端训练,GPU也需要同CPU进行异构。
目前,英特尔在人工智能芯片领域主要通过三条路径:1)通过并购快速积累人工智能芯片相关的技术和人才,并迅速完成整合。英特尔在收购了Altera后,还先后收购了Nervana、Movidius与Mobileye等初创企业。在完成上述一系列并购之后,英特尔设立了AI事业群,整合了Xeon、Xeon Phi、Nervana、Altera、Movidius等业务和产品,同时将原有的自动驾驶业务板块并入Mobileye。2)建立多元的产品线。目前,英特尔正建构满足高性能、低功耗、低延迟等差异化芯片解决方案,除了Xeon外,包括可支持云端服务Azure的Movidius VPU与FPGA。3)通过计算平台等产品,提供强大的整合能力,优化AI计算系统的负载,提供整体解决方案。
在英特尔收购的这些企业中,除了前面已经提到的Altera、Mobileye之外,Nervana也非常值得关注。2016年8月,英特尔斥资超过3.5亿美元收购这家员工人数不超过50人的创业公司,但是经过不到三年的成长,这家公司已经成为英特尔AI事业部的主体。依托Nervana,英特尔成功在2017年10月推出了专门针对机器学习的神经网络系列芯片,目前该芯片已经升级至第二代,预计2019年下半年将正式量产上市,该芯片在云端上预计能和英伟达的GPU产品一较高下。
(4)AMD
美国AMD半导体公司专门为计算机、 通信和消费电子行业设计和制造各种创新的微处理器(CPU、 GPU、 APU、 主板芯片组、 电视卡芯片等),以及提供闪存和低功率处理器解决方案, 公司成立于1969 年。 AMD 致力为技术用户——从企业、 政府机构到个人消费者——提供基于标准的、 以客户为中心的解决方案。2017年12月Intel和AMD 宣布将联手推出一款结合英特尔处理器和 AMD 图形单元的笔记本电脑芯片。目前 AMD 拥有针对 AI 和机器学习的高性能 Radeon Instinc 加速卡,开放式软件平台 ROCm 等。AMD将研发下一代VEGA架构GPU芯片,参与竞争。
总之,对于云端的Training(也包括Inference)系统来说,业界比较一致的观点是竞争的核心不是在单一芯片的层面,而是整个软硬件生态的搭建。NVIDIA的CUDA+GPU、Google的TensorFlow+TPU2.0,巨头的竞争也才刚刚开始。
2、云端推理
相对于Training市场上NVIDIA的一家独大,Inference市场竞争则更为分散。若像业界所说的深度学习市场占比(Training占5%,Inference占95%),Inference市场竞争必然会更为激烈。
在云端推理环节,虽然GPU仍有应用,但并不是最优选择,更多的是采用异构计算方案(CPU/GPU+FPGA/ASIC)来完成云端推理任务。
FPGA领域,四大厂商(Xilinx/Altera/Lattice/Microsemi)中的Xilinx和Altera(被Intel收购)在云端加速领域优势明显。Altera在2015年12月被Intel收购,随后推出了Xeon+FPGA的云端方案,同时与Azure、腾讯云、阿里云等均有合作;Xilinx则与IBM、百度云、AWS、腾讯云合作较深入,另外Xilinx还战略投资了国内AI芯片初创公司深鉴科技。目前来看,云端加速领域其他FPGA厂商与Xilinx和Altera还有很大差距。
ASIC领域,应用于云端推理的商用AI芯片目前主要是Google的TPU1.0/2.0。其中,TPU1.0仅用于DatacenterInference应用。它的核心是由65,536个8-bitMAC组成的矩阵乘法单元,峰值可以达到92TeraOps/second(TOPS)。有一个很大的片上存储器,一共28MiB。它可以支持MLP,CNN和LSTM这些常见的神经网络,并且支持TensorFLow框架。它的平均性能(TOPS)可以达到CPU和GPU的15到30倍,能耗效率(TOPS/W)能到30到80倍。如果使用GPU的DDR5memory,这两个数值可以达到大约GPU的70倍和CPU的200倍。TPU2.0既用于训练,也用于推理。企业介绍如下:
(1)寒武纪
寒武纪是中国智能芯片领域的先行者,公司已经退出智能云服务器、智能终端以及智能机器人的核心处理器芯片。
寒武纪MLU100智能处理卡搭载了寒武纪MLU100云端智能芯片,为云端推理提供强大的运算能力支撑。与传统架构处理器相比,MLU100在处理人工智能任务时可获得巨大的性能和能效提升,是真正适合人工智能的处理器。MLU100云端智能芯片的等效理论计算能力高达128TOPS, 支持4通道64bit。
(2)深鉴科技
深鉴科技成立于 2016 年,总部在北京。由清华大学与斯坦福大学的世界顶尖深度学习硬件研究者创立。深鉴科技于 2018 年 7 月被赛灵思收购。深鉴科技将其开发的基于 FPGA 的神经网络处理器称为 DPU。
到目前为止,深鉴公开发布了两款 DPU:亚里士多德架构和笛卡尔架构,其中,亚里士多德架构是针对卷积神经网络 CNN 而设计;笛卡尔架构专为处理 DNN/RNN 网络而设计,可对经过结构压缩后的稀疏神经网络进行极致高效的硬件加速。相对于 Intel XeonCPU 与 Nvidia TitanX GPU,应用笛卡尔架构的处理器在计算速度上分别提高 189 倍与 13 倍,具有 24,000 倍与 3,000 倍的更高能效。
(3)阿里巴巴:推出自研神经网络处理芯片,同时加速对AI企业投资布局
阿里巴巴作为国内AI领域的领军企业,在底层算力、算法技术以及应用平台方面都有较强积累。同Google类似原因,阿里巴巴也在近年来开始开发AI芯片,同时加大对相关领域的投资布局。
2017年,阿里巴巴成立阿里达摩院,研究领域之一就是AI芯片技术。2018年4月,阿里达摩院对外宣布正研发一款Ali-NPU神经网络芯片,预计将在2019年下半年问世。这款芯片将主要应用于图像视频分析、机器学习等AI推理计算。
阿里巴巴在自研AI芯片之前,主要在通过投资的方式布局AI芯片领域。目前,寒武纪、深鉴科技、杭州中天微等都有阿里巴巴的入股,其中2016年1月份还成为了AI芯片设计企业杭州中天微的第一大股东。
(4)百度:通过自研、合作以及投资等多种方式部署AI芯片
百度 2017 年 8 月 Hot Chips 大会上发布了 XPU,这是一款 256 核、基于 FPGA 的云计算加速芯片。合作伙伴是赛思灵(Xilinx)。 XPU 采用新一代 AI 处理架构,拥有 GPU 的通用性和 FPGA 的高效率和低能耗,对百度的深度学习平台 PaddlePaddle 做了高度的优化和加速。据介绍, XPU 关注计算密集型、基于规则的多样化计算任务,希望提高效率和性能,并带来类似 CPU 的灵活性。
3、边缘端芯片
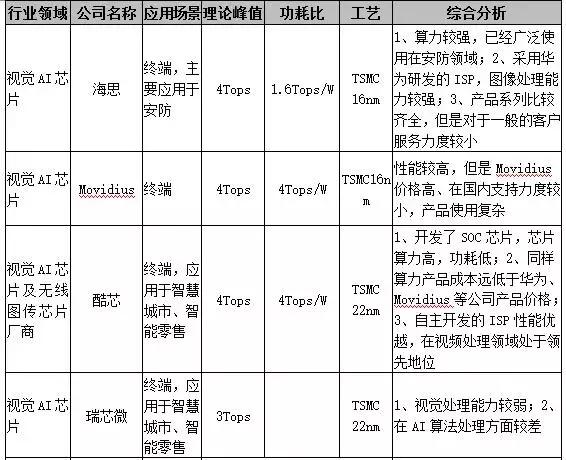
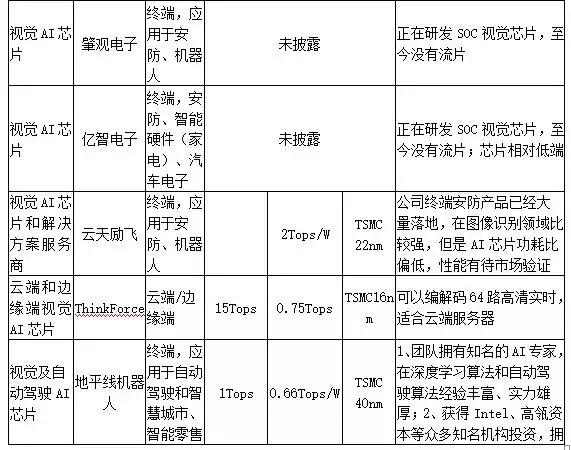
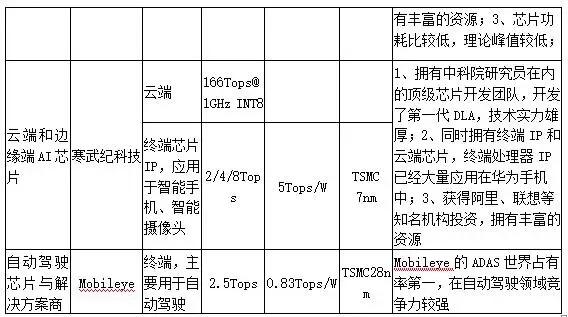
边缘端(设备端)推理的应用场景更为多样化,包括智能手机、ADAS、智能摄像头、语音交互、VR/AR等设备需求各异,需要更为定制化、低功耗、低成本的嵌入式解决方案,这就给了创业公司更多机会,市场竞争生态也会更加多样化。其中,智能视觉和自动驾驶领域公司发展较快,主要竞争公司如下表所示:
表1:视觉AI芯片公司
资料来源:公开资料,汉理资本整理
(1)智能视觉AI芯片
1)华为海思
华为海思拥有适用于移动手机和智能摄像头等多款芯片,在国内智能视觉AI芯片领域处于领导者地位。
麒麟 970 搭载的神经网络处理器 NPU 采用了寒武纪 IP,如图 12 所示。麒麟 970 采用了 TSMC 10nm 工艺制程,拥有 55 亿个晶体管,功耗相比上一代芯片降低 20%。 CPU 架构方面为 4 核 A73+4 核 A53 组成 8 核心,能耗同比上一代芯片得到 20%的提升; GPU 方面采用了 12 核 Mali G72 MP12GPU,在图形处理以及能效两项关键指标方面分别提升 20%和50%; NPU 采用 HiAI移动计算架构,在 FP16 下提供的运算性能可以达到 1.92 TFLOPs,相比四个 Cortex-A73 核心,处理同样的 AI 任务,有大约具备 50 倍能效和 25 倍性能优势。
海思已经量产的Hi3559A标称算力4Tops,功耗比为1.61.6Tops/W,可以应用于安防、新零售等场景。Hi3559A算力较强,采用华为研发的ISP,图像处理能力较强,产品系列比较齐全,已经广泛使用在安防领域。但是海思对于一般的客户服务力度较小。
2)Movidius(被Intel收购)
2016 年9月,Intel 发表声明收购了 Movidius。 Movidius 专注于研发高性能视觉处理芯片。其最新一代的 Myriad2 视觉处理器主要由 SPARC 处理器作为主控制器,加上专门的DSP 处理器和硬件加速电路来处理专门的视觉和图像信号。这是一款以 DSP 架构为基础的视觉处理器,在视觉相关的应用领域有极高的能耗比,可以将视觉计算普及到几乎所有的嵌入式系统中。
该芯片已被大量应用在 Google 3D 项目的 Tango 手机、大疆无人机、 FLIR 智能红外摄像机、海康深眸系列摄像机、华睿智能工业相机等产品中,但是Movidius价格高、在国内支持力度较小,产品使用相对复杂,对于中小客户应用起来不是很友好。
3)酷芯微
上海酷芯微电子有限公司成立于2011年7月,是由三位毕业于复旦大学、有近20年集成电路领域连续成功创业的团队创办,是国内领先的智能视觉AI芯片和无线图传芯片设计公司。公司成立之初是大疆公司无线图传芯片独家供应商,2015年开始研发智能视觉芯片,并于2017年发布并量产第一代的智能视觉终端AI芯片AR9101T,2018年发布第二代智能视觉终端AI芯片AR9201,算力为1.2Tops,公司成立至今已经成功流片并量产6颗芯片。公司智能视觉终端AI芯片主要应用于边缘端计算,应用场景包括智能安防、新零售、机器人等领域,在智能视觉领域技术领先,客户包括国内顶级电商公司、大疆、瑞为、特斯联等。
图17:酷芯微AI芯片产品介绍

资料来源:汉理资本
公司AI芯片产品不同部分公司的DLA,公司产品采用的是超高集成度先进工艺的SoC,具有高功效比、强算力支持,拥有完善的工具链,可以实现跨平台AI算法迁移,采用自主研发的ISP,性能可以媲美安霸和华为海思,提升画质的同时降低数据传输带宽,充分发挥DSP/DLA性能,在智能视觉分析领域竞争力较强,具体如下:
图18:酷芯产品特性

资料来源:汉理资本
公司第三代边缘端AI芯片AR9301已经进入研发后期,预计2019年下半年流片并量产。第三代边缘端AI芯片AR9301计划采用TSMC22nm工艺,采用全新架构的DLA,算力高达4Tops,AI部分功耗仅为0.8W,功耗比非常高,另外DDR位宽16bit,DDR带宽与算力的合理匹配,实现超高有效深度学习算力。
整体来看,酷芯微公司开发了SOC芯片,芯片算力高,功耗低,自主开发的ISP性能优越,在视频处理领域处于领先地位,酷芯微公司同样算力产品成本远低于华为、Movidius等公司产品价格,公司对于客户服务支持力度较大,可以广泛应用于智能安防、新零售等边缘端计算场景。
4)中星微
1999年由多位来自硅谷的博士企业家在北京中关村科技园区创建了中星微电子有限公司, 启动并承担了国家战略项目——“星光中国芯工程”,致力于数字多媒体芯片的开发、设计和产业化。
2016 年初,中星微推出了全球首款集成了神经网络处理器(NPU)的 SVAC 视频编解码 SoC,使得智能分析结果可以与视频数据同时编码,形成结构化的视频码流。该技术被广泛应用于视频监控摄像头,开启了安防监控智能化的新时代。自主设计的嵌入式神经网络处理器(NPU)采用了“数据驱动并行计算” 架构,专门针对深度学习算法进行了优化,具备高性能、低功耗、高集成度、小尺寸等特点,特别适合物联网前端智能的需求。
5)灵汐科技
灵汐科技于 2018 年 1 月在北京成立,联合创始人包括清华大学的世界顶尖类脑计算研究者。公司致力于新一代神经网络处理器(Tianjic)开发, 特点在于既能够高效支撑现有流行的机器学习算法(包括 CNN, MLP, LSTM 等网络架构),也能够支撑更仿脑的、更具成长潜力的脉冲神经网络算法;使芯片具有高计算力、高多任务并行度和较低功耗等优点。软件工具链方面支持由 Caffe、 TensorFlow 等算法平台直接进行神经网络的映射编译,开发友善的用户交互界面。 Tianjic 产品将广泛应用于数据中心的云服务、边缘计算以及安防等各种AI落地行业,助力人工智能的落地和推广。
(2)自动驾驶AI芯片
1)地平线机器人(Horizon Robotics)
地平线机器人成立于 2015 年,总部在北京,创始人是前百度深度学习研究院负责人余凯。BPU(Brain Processing Unit)是地平线机器人自主设计研发的高效人工智能处理器架构IP,支持 ARM/GPU/FPGA/ASIC 实现,专注于自动驾驶、人脸图像辨识等专用领域。
2017年,地平线发布基于高斯架构的嵌入式人工智能解决方案,将在智能驾驶、智能生活、公共安防三个领域进行应用,第一代 BPU芯片“盘古” 目前已进入流片阶段,能支持 1080P 的高清图像输入,每秒钟处理 30 帧,检测跟踪数百个目标。地平线的第一代 BPU 采用 TSMC 的 40nm工艺,相对于传统 CPU/GPU, 能效可以提升 2~3 个数量级(100~1,000 倍左右)。
2)Mobileye
公司是以色列一家生产协助驾驶员在驾驶过程中保障乘客安全和减少交通事故的视觉系统的公司。已投身研发 12 年并收获了前所未有的技术知识。公司在单目视觉高级驾驶辅助系统 (ADAS) 的开发方面走在世界前列,提供芯片搭载系统和计算机视觉算法运行 DAS 客户端功能。2017年3月13日,英特尔正式宣布,以每股63.54美元现金收购Mobileye。Mobileye的ADAS世界占有率第一,在自动驾驶领域竞争力非常强。
(3)手机芯片
高通:在智能手机芯片市场占据绝对优势的高通公司,也在人工智能芯片方面积极布局。据高通提供的资料显示,其在人工智能方面已投资了 Clarifai 公司和中国“专注于物联网人工智能服务” 的云知声。而早在 2015 年 CES 上,高通就已推出了一款搭载骁龙 SoC 的飞行机器人——Snapdragon Cargo。高通认为在工业、农业的监测以及航拍对拍照、摄像以及视频新需求上,公司恰





 021-61406392
021-61406392